Windows 清除DNS快取
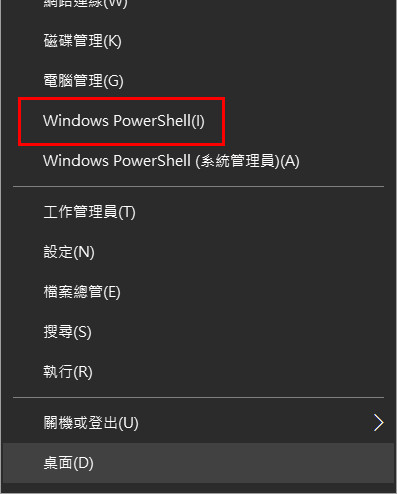
- 滑鼠移至左下角開始功能表,按右鍵。
- 選擇 Windows PowerShell
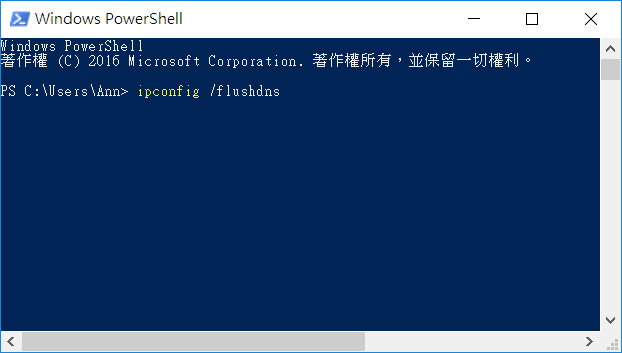
- 貼上下方文字
ipconfig /flushdns
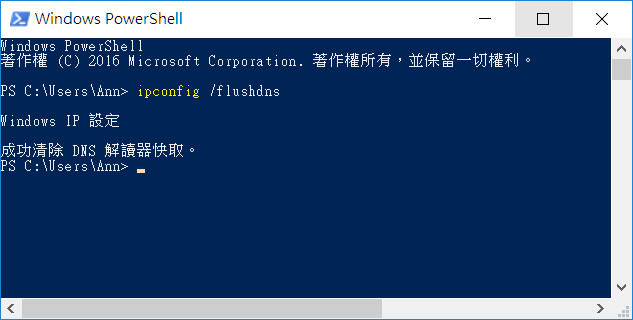
- 清除DNS完成
[……]
這是一個很常用的功能,有時我們在處理表單發送後的資料,有時常常會多按了一些空白,這些空白可能會導致資料錯誤,或是資料轉檔時,明明看資料沒錯,怎麼就對不起來,比如說我剛剛的例子,搞了我好久
<?php
$str=" 測試字串,前後空白都會被清除 ";
echo trim("$str");
?>API回傳Json資料,怎麼看pickUpDateTime,都是沒值的,我就用empty()來做判斷,卻怎麼都友值,弄了半天是空白字元,我也不懂這API主人為什麼空值不拋要拋一堆空白自原來害人
[toStoreDateTime] => 2017/08/11 00:00:00 [pickUpDateTime] => [omTranMode] => 3203 [Status] => 50 [omReceName] => 王小明
不管!!至少問題找到了,問題就解決一半了,接著就是在用empty()作空值判斷前,先用trim()去過濾這些該死的空白
<?php $pickUpDateTime =" "; echo (empty(trim($pickUpDateTime )))?1:0; ?>
[……]
本篇使用 Javascript , 若想用jQuery的方法,可參考本站另一篇
本篇提供兩種方法,擇一使用
/*
VECTOR COOL
https://vector.cool
*/
function getUrlParameter(sParam) {
var sPageURL = decodeURIComponent(window.location.search.substring(1)),
sURLVariables = sPageURL.split('&'),
sParameterName,
i;
for (i = 0; i < sURLVariables.length; i++) {
sParameterName = sURLVariables[i].split('=');
if (sParameterName[0] === sParam) {
return sParameterName[1] === undefined ? true : sParameterName[1];
}
}
};/*
VECTOR COOL
https://vector.cool
*/
function getURLParameter(name, url) {
if (!url) url = window.location.href;
name = name.replace(/[\[\]]/g, "\\$&");
var regex = new RegExp("[?&]" + name + "(=([^&#]*)|&|#|$)"),
results = regex.exec(url);
if (!results) return null;
if (!results[2]) return '';
return decodeURIComponent(results[2].replace(/\+/g, " "));
}
/*
VECTOR COOL
https://vector.cool
*/
var tech = getUrlParameter('technology');
var blog = getUrlParameter('blog');[……]
本篇使用 jQuery方法, 若覺得jQuery的方法很大包,可參考本站另一篇
QueryString.js
把第一段的程式碼放到一個名叫 QueryString.js 的檔案,以後需要時再去引入這支檔案就可。
/*
VECTOR COOL
https://vector.cool
*/
(function($) {
$.QueryString = (function(paramsArray) {
let params = {};
for (let i = 0; i < paramsArray.length; ++i)
{
let param = paramsArray[i]
.split('=', 2);
if (param.length !== 2)
continue;
params[param[0]] = decodeURIComponent(param[1].replace(/\+/g, " "));
}
return params;
})(window.location.search.substr(1).split('&'))
})(jQuery);/*
VECTOR COOL
https://vector.cool
*/
//Get a param
$.QueryString.param
//-or-
$.QueryString["param"]
//This outputs something like...
//"val"
//Get all params as object
$.QueryString
//This outputs something like...
//Object { param: "val", param2: "val" }
//Set a param (only in the $.QueryString object, doesn't affect the browser's querystring)
$.QueryString.param = "newvalue"
//This doesn't output anything, it just updates the $.QueryString object
//Convert object into string suitable for url a querystring (Requires jQuery)
$.param($.QueryString)
//This outputs something like...
//"param=newvalue¶m2=val"
//Update the url/querystring in the browser's location bar with the $.QueryString object
history.replaceState({}, '', "?" + $.param($.QueryString));
//-or-
history.pushState({}, '', "?" + $.param($.QueryString));[……]
轉至:V123 DEV – WordPress 中文開發團隊
可能因為某些原因,會需要更換WP網址,但之前寫的文章SEO好不容易做起來,大部分的頁面搜尋引擎也都收錄了,這樣不是太浪費了,SEO的部分等於一切重來,雖然換網址真的對SEO很傷,但沒辦法的時候我們只能將傷害降到最低。
下圖,新網站的”固定網址“設置,
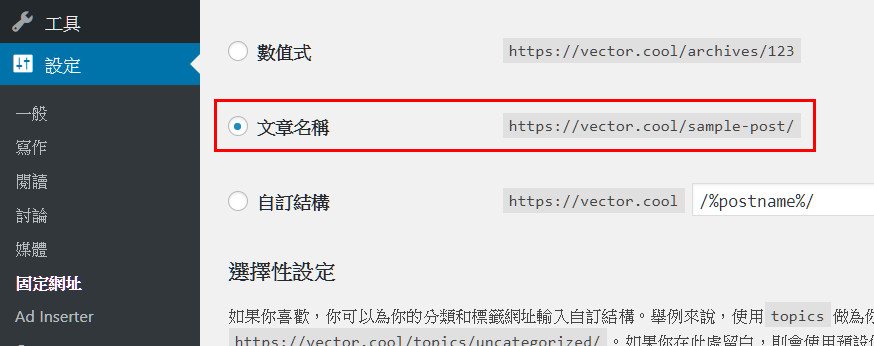 設定WordPress固定網址,請務必確定與舊網站設置相同 – V123 DEV
設定WordPress固定網址,請務必確定與舊網站設置相同 – V123 DEV
做完第一步,再來就是要將舊網域的網址轉至新網域的網址,但參數不變,讓每一篇文章都可以搬家到新網址
http://old-domain.com/example/
轉到
http://new-domain.com/example/
設定舊站根目錄下的 .htaccess 檔,把所有原有的值都刪了,添加下面兩行
所有網址就順利的重定向到新網址
如果您已經確定完成上述兩步驟,再來
當然是要通知Google大神,拜拜碼頭,說我要換網址了
登入Google帳戶,進入Google Search Console,先新增新網站網址,並通過驗證,至於怎麼新增網址到 Google Search Console 請Google一下,很簡單,這邊不多贅述。
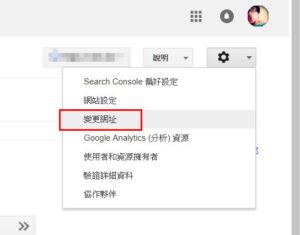 新增完成後在右上角下拉選單選擇舊網站網址,按一下右側的齒輪icon設定,選擇變更網址選項 – V123 DEV
新增完成後在右上角下拉選單選擇舊網站網址,按一下右側的齒輪icon設定,選擇變更網址選項 – V123 DEV
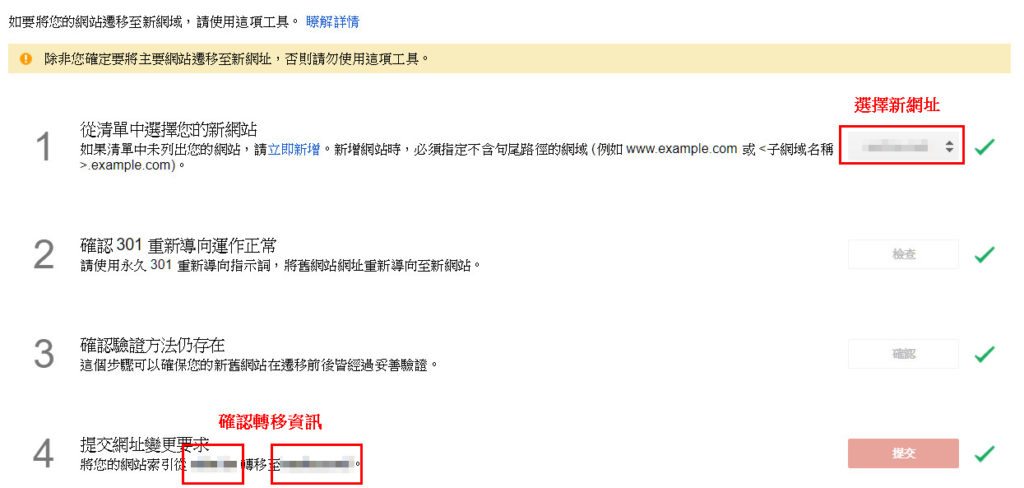 將會一步一步地確認,最後提交申請 – V123 DEV參考資料:
將會一步一步地確認,最後提交申請 – V123 DEV參考資料:https://v123.tw/wordpress-seo-%E6%8F%9B%E7%B6%B2%E5%9D%80%E5%BE%8C%E4%B8%80%E5%AE%9A%E8%A6%81%E5%81%9A%E7%9A%843%E4%BB%B6%E4%BA%8B/[……]
jQuery 並沒有 .hasAttr() 用於判斷某一屬性是否存在,所以透過下面代碼來檢查
此代碼優點在於可檢查屬性是否存在,並檢查是否為空值
/**
* VECTOR COOL
* https://vector.cool
*/
var attr = $(this).attr(‘name’);
if (attr && attr !== false) {
// Element has this attribute
}
[……]
$string = '<img border="0" src="/images/image.jpg" alt="Image" width="100" height="100" />';
preg_match('@src=["']([^"']+)["']@', $string, $result);
print_r($result);
Array
(
[0] => src="/images/image.jpg"
[1] => /images/image.jpg
)[……]